

Em alta

100%
Livro do Ivan Nunes Silva: Redes Neurais Artificiais para engenharia e
ciências aplicadas
L iv ro d o I v a n N u n e s S i lv a : Re d e s N e u r a is A r t if ic i a i s p a r a e n g e nh a r i a e
ci ê n c i a s a p l i c a d a s
Ca p . 1 : p á gi n a s 4 3 - 44 ;
Ca p . 2 : p á gi n a s 5 4 - 55 ;
Ca p . 3 - e xe r c íc io s 6 a 1 0 ;
Ca p . 4 - e xe r c íc io s 7 a 1 0 .
LISTA 1 - RNA
Discente: Aden Hercules Pinto de Azevedo
Professora: Carolina Watanabe
Capítulo 01
Exercício 1 = Apresentação de um conjunto de valores que rep resentam as
variáveis de entrad a do n eurônio. Multiplicação de ca da entrada do neurônio pelo
seu respectivo pe so sináptico. Ob tenção do potencial de ativação produzido pela
soma ponderada dos sinais de entrada, subtraindo -se o limiar de ativação.
Aplicação de uma função de ativação apropriada, tendo -se como objet ivo limitar a
saída do neurônio. Compilação da saída a partir da aplicação da função de ativação
neural em relação ao seu potencial de ativação.
Exercício 2 = Seu principal objetivo é limitar a saída do neurônio dentro de um
intervalo de valores razoáveis a serem assumidos pela sua própria imagem
funcional.
Exercício 3 = O tempo de p rocessamento do n eurônio artificial é muito su perior ao
neurônio bioló gico. Mas, o processamento cerebral é infin ita s vezes mais rápido que
uma rede neural artificial na maioria dos casos, pois os neurônios da rede neu ral
biológica trab alham com alto grau de paralelismo entre si, a o passo que para os
neurônios a rtificiais este nível de paralelismo é bem limitado, poi s a ma ioria dos
computadores é constituída de máquinas tipicamente sequenciais.
Exercício 4 = É a variável que especifica qual será o patamar apropriado para que o
resultado p roduzido pelo combinador linea r possa gerar um valor de disparo em
direção a saída do neurônio.


Crie sua conta grátis para liberar esse material. 🤩
Já tem uma conta?
Ao continuar, você aceita os Termos de Uso e Política de Privacidade
Exercício 5 = Ad aptação por experiência: parâmetros internos da rede, tipicamente
seus pesos sinápticos, são ajustados a partir da apresentação su cessiva de
exemplos (amostras e medidas relacionados ao comportamento do processo.
Habilidade de generalização: após o p rocesso de treinamento, a rede é capaz de
generalizar o
conhecimento adquirido, possibilitando a estimação de soluções que eram até então
desconhecidas.
Exercício 6 Logística: Saída: valores entre 0 e 1. Possui uma f lexão mas c ontinua
estritamente crescente. O Beta vai de finir se o nível de inclinação vai se aproximar
mais do eixo Y ou não. Qu anto maior o B eta, maior a ap roximação. Quando ele
tende ao infinito, ela se aproxima da função degrau.
Tangente Hiperbólica: Sa ída: valores entre -1 e 1. Possui uma flexão mas continua
estritamente crescente. O Beta vai def inir se o nível de inclina ção vai se aproxim ar
mais do eixo Y ou não. Qu anto maior o B eta, maior a ap roximação. Quando ele
tende ao infinito, ela se aproxima da função bipolar.
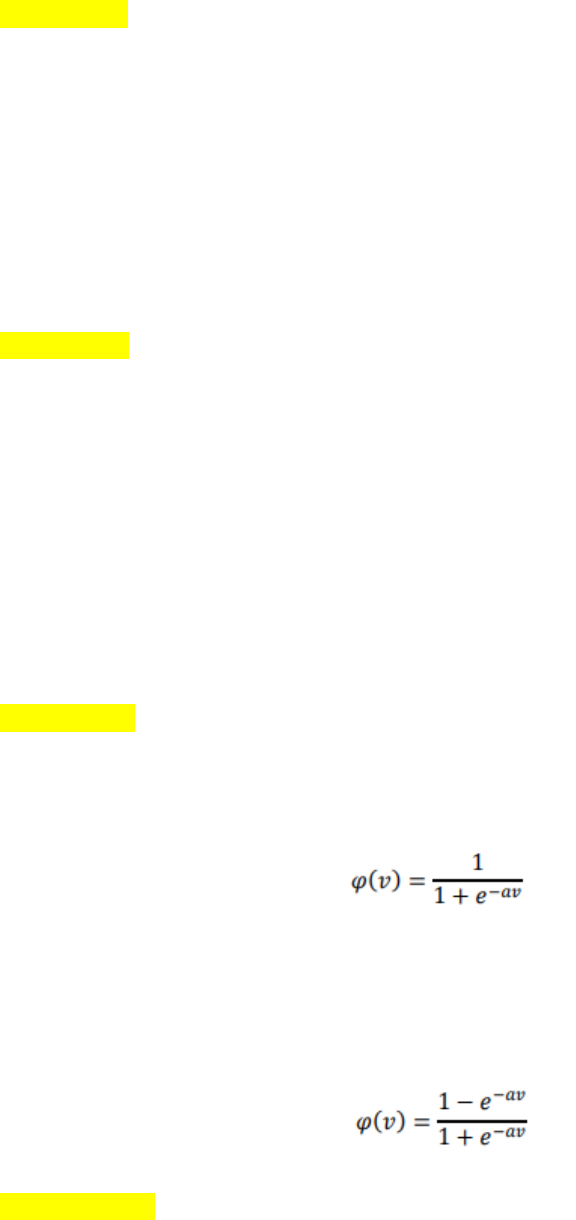
Exercício 7 = Logistica: Em que a é o parâmetro de inclinação da fu nção sigmóide,
a qual está asso ciada ao nível d e inclinação da função em relaçã o ao seu ponto de
inflexão. Sua expressão matemática é dada por:
Tangente Hiperbólica: Ao contrário da função sigmóide, o resultado da saída
sempre assumirá valores reais entre entre -1 e 1. Sua e xpressão matemática é dada
por:
Exercício 8 = Logística: útil para produzir probabilidades em problemas de
classificação binária, o u seja, trab alha com o pertencer ou não pertencer à
determinada classe.
Crie sua conta grátis para liberar esse material. 🤩
Já tem uma conta?
Ao continuar, você aceita os Termos de Uso e Política de Privacidade
Tangente Hiperbólica: boa para ativação de camadas escondidas, pois ela está
centrada em zero, não po ssui tanta extremidade quanto a logística. S ua derivada
converge em 0 e mais rapidamente.
Exercício 9 = O p arâmetro de velocidade de uma rede neural artif icial está
basicamente relacionado com o número de o perações por segundo dos
computadores. Considerando um clock da ordem de gigahertz, e ntão um período de
processamento dos neurônios artificiais fica na grandeza de nanossegundo.
Exercício 10 = Foi verificado que sua aplicação demasiada útil e bem sucedida em
diversos setores da sociedade: saúde, eco nomia, tran sporte, educação, indústria de
máquinas, tudo graças a su a capacida de adaptativa, e ao fa to de po der induzi -la a
agir em prol da solução de casos em um nicho ou problema específico.
Capítulo 2
Exercício 1 = Por lote d e pa drão: o s ajustes efetuados nos vetores d e pesos das
redes e em seus limiares só são efetivados após a apresentação de todo o conjunto
de treinamento, pois cada passo de ajuste leva em consideração o total de desvios
observados nas amostras de treinamento frente aos respectivos valores desejados
para as suas saídas.
Padrão por padrão: o s ajustes nos pesos e limiares das red es são efetuados após a
apresentação de cada amostra de treinamento, portanto, após a execução do passo
de ajuste, a respectiva amostra pode ser descartada.
Exercício 2 = Não necessariamente, feedforward de camadas múltipla s o número
de camadas escondidas e seus respectivos n eurônios constituintes dependem,
sobretudo, d o tipo e da complexidade do prob lema a ser mapeado pe l a rede, assim
como da quantidade e da qualidade dos dados disponíveis sobre o problema.
Exercício 3 = O n úmero de camadas escondidas e seus respectivos neurônios
constituintes dependem, sobretudo, do tipo e da complexidade do problema a ser
Crie sua conta grátis para liberar esse material. 🤩
Já tem uma conta?
Ao continuar, você aceita os Termos de Uso e Política de Privacidade
mapeado pela rede, assim como da quantidade e da qualidade d os dados
disponíveis sobre o problema.
Exercício 4 = Recorrente: Saídas dos neurônios são realimentadas como sinais de
entrada para outros neurônios. Realimentação as qualif icam para processamento
dinâmico de informações.
Feedforward: na ca mada simples, é constituída de uma camada de entrada e única
camada de neurônios, que é a própria saída. O fluxo de informações segue sempre
numa única direção (unidirecional). Na camada múltipla: Presença d e uma ou mais
camadas n eurais escondida s. Quantidade de camadas escondidas e de neurônios
dependem, sobretudo, do tipo e complexidade do problema.
Exercício 5 = Po dem ser utilizadas em sistemas variantes em relação ao tempo,
como previsão de séries temporais, otim ização e identificação de sistemas, controle
de processos, etc.
Exercício 6 =
Exercício 7 = O processo de treinamento consiste da a plicação de passos
ordenados que sejam nece ssários para sint onização dos p esos sinápticos e lim iares
de seus neurônios, tendo-se como objetivo final a generalização de soluções a
serem produzidas pelas suas saídas, cujas respostas sã o representativas do
sistemas físico em que estão mapeando.
O algoritmo de aprendizagem é o con junto desse s passos ordenados visando o
treinamento da rede. Duran te o proce sso de treinamento de redes neurais artificiais,
cada apresentação co mpleta das amostras p ertencentes ao subconjunto de
Crie sua conta grátis para liberar esse material. 🤩
Já tem uma conta?
Ao continuar, você aceita os Termos de Uso e Política de Privacidade

treinamento, visando, sobretudo, o ajuste dos pesos sinápticos e limiares de seus
neurônios, será denominada de época de treinamento.
Exercício 8 = No modelo de aprendizagem de máquina supervisionada
conseguimos dar o s pesos ou calibrar o nível de a ssertividade e de precisão de um
modelo,dessa forma tende a ter uma necessidade de d isponibilizar uma tabela de
dados(E/S) representativa do processo, também conhecida co mo tabela
atributo/valores. Os pesos sinápticos e lim iares são continuamente ajustados diante
a aplicação de ações comparativas.
Diferente do supervisionado, durante a ap licação de um a lgoritmo de
aprendizado baseado e m treinamento, inexistem as respectivas saídas desejadas.
Os pesos sinápticos e limiares dos neurônios da rede são então ajustados pelo
algoritmo de aprendizado de f orma a refletir esta representação internamente dentro
da própria rede.
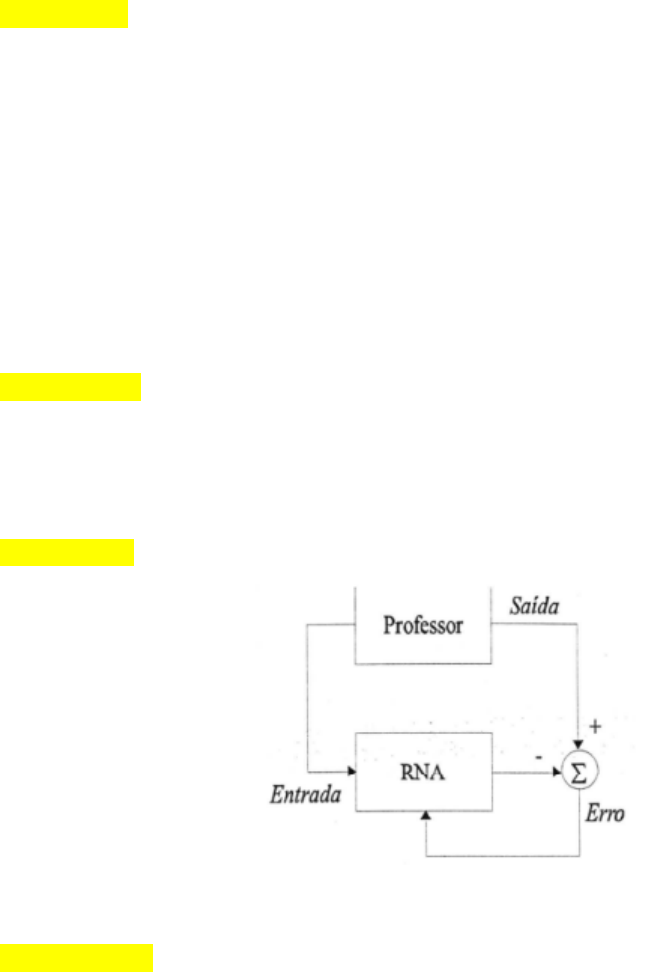
Exercício 9 =Treinamento supervisionado: consiste em se ter disponível disponível,
considerando cada amostra dos sinais de entrada, a s resp ectivas saídas desejadas.
Cada amostra de trein amento é en tão composta pelos sina is de entradas e suas
correspondentes saídas. Comporta como se houvesse um “professor” ensinando
para a rede qual seria a respo sta correta para cada amostra apresentada.
Treinamento com reforço: avaliam constantemente a defasagem de valor entre as
respostas produzidas pela rede em relação à respectiva saída desejada. Os
algoritmos de aprendizagem utilizados ajustam os parâmetros internos dos
neurônios ba seando-se em quaisquer informações quantitativas ou qualitativas
advindas da interação com o sistema que esta sen do mapeado, as quais sã o e ntão
utilizadas para medir o desempenho do aprendizado.
Exercício 10 = Os algoritmos de apr endizado utilizados no trein amento com reforço
ajustam os parâmetros internos dos neurôn ios baseando -se em quaisquer
informações quantitativas ou qualitativas advindas de interação com o sistema. O
processo de treinamento da rede é realizado por tentativa e erro, pois a única
resposta disponível pa ra u ma determinada entrada é se é satisfatória ou nã o. Se for
considerada satisfatória, incrementa nos pesos sinápticos e limiares são então
gradualmente efetuados visando reforçar esta condição comportamental.
Crie sua conta grátis para liberar esse material. 🤩
Já tem uma conta?
Ao continuar, você aceita os Termos de Uso e Política de Privacidade
Diversos algoritmos que utilizam treinamento com reforço são baseados em
métodos estocásticos que selecionam probabilísticamente suas ações de ajustes.
Capítulo 03
Exercício 06 = A quan tidade de épocas necessárias pa ra a convergência varia em
função dos valores iniciais que foram a tribuídos a o vetor de pesos {w}, assim com o
da d isposição espacial das amostras de treinamento e do valor especificado pa ra a
taxa de aprendizado.
Exercício 7 = O resultado vai variar toda vez que o a lgoritmo for exe cutado, en tão
mesmo tendo as mesmas amostras, o resultado será diferente.
Exercício 8 = Se a saída produzida pelo Perceptron e stá não coincidente com a
saída dese jada, os p esos sinápticos e limiares da rede serão então incrementados
proporcionalmente a os valores de seus sinais de entrada; caso contrário, a saída
produzida pela rede é igual ao valor de sejado, os pesos sinápticos e limiar
permanecerão então inalterados. Este processo é repetido, sequencialmente para
todas as amo stras de treinamento, até que a saída produzida pelo Perceptron seja
similar à saída desejada de cada amostra.
Exercício 9 = Não é possível, p ois na figura os d ados não são linearmente
separáveis, e a técnica do perceptron não permite isso.
Exercício 10 = T ipicamente, devido às suas caract erísticas estruturais, a s fun ções
de a tivação normalmente usadas no Perceptron sã o a função degrau ou de grau
bipolar. Assim, independente da fu nção de a tivação a ser utilizada, tem -se apenas
duas possibilidades de valores a serem produzidos pela sua saída, ou seja, valor 0
ou 1 se for considerada a função de ativação degrau, ou ainda, valor -1 ou 1 se f or
assumida a função degrau bipolar.
Crie sua conta grátis para liberar esse material. 🤩
Já tem uma conta?
Ao continuar, você aceita os Termos de Uso e Política de Privacidade
Capítulo 4
Exercício 7 =
Exercício 8 = Verdadeira. A rede Adaline nã o tem relação f orte de inicialização dos
pesos à luz dos valores f inais do hiperplano ideal. O hiperplano de separabilidade
sempre será o mesmo.
Exercício 9 = Não será pois varia em função da disposição espacial d as amostras
de treinamento e do valor assumido para a taxa de aprendizado.
Exercício 10 = S im, há necessidade de atualização do operador, devido a variação
é a que vai fornecer um indicativo do m elhor resu ltado em que o processo de
treinamento está sendo executado. Assim sendo caso erro, o processo minimiza o
erro quadrático em relação às amostras disponíveis para o a prendizado e m f orma
decrescente no decorrer das épocas.
Crie sua conta grátis para liberar esse material. 🤩
Já tem uma conta?
Ao continuar, você aceita os Termos de Uso e Política de Privacidade
Prévia do material em texto
Livro do Ivan Nunes Silva: Redes Neurais Artificiais para engenharia e
ciências aplicadas
Livro do Ivan Nunes Silva: Redes Neurais Artificiais para engenharia e
ciências aplicadas
Cap. 1: páginas 43-44;
Cap. 2: páginas 54-55;
Cap. 3 - exercícios 6 a 10;
Cap. 4 - exercícios 7 a 10.
LISTA 1 - RNA
Discente: Aden Hercules Pinto de Azevedo
Professora: Carolina Watanabe
Capítulo 01
Exercício 1 = Apresentação de um conjunto de valores que representam as
variáveis de entrada do neurônio. Multiplicação de cada entrada do neurônio pelo
seu respectivo peso sináptico. Obtenção do potencial de ativação produzido pela
soma ponderada dos sinais de entrada, subtraindo-se o limiar de ativação.
Aplicação de uma função de ativação apropriada, tendo-se como objetivo limitar a
saída do neurônio. Compilação da saída a partir da aplicação da função de ativação
neural em relação ao seu potencial de ativação.
Exercício 2 = Seu principal objetivo é limitar a saída do neurônio dentro de um
intervalo de valores razoáveis a serem assumidos pela sua própria imagem
funcional.
Exercício 3 = O tempo de processamento do neurônio artificial é muito superior ao
neurônio biológico. Mas, o processamento cerebral é infinitas vezes mais rápido que
uma rede neural artificial na maioria dos casos, pois os neurônios da rede neural
biológica trabalham com alto grau de paralelismo entre si, ao passo que para os
neurônios artificiais este nível de paralelismo é bem limitado, pois a maioria dos
computadores é constituída de máquinas tipicamente sequenciais.
Exercício 4 = É a variável que especifica qual será o patamar apropriado para que o
resultado produzido pelo combinador linear possa gerar um valor de disparo em
direção a saída do neurônio.
Exercício 5 = Adaptação por experiência: parâmetros internos da rede, tipicamente
seus pesos sinápticos, são ajustados a partir da apresentação sucessiva de
exemplos (amostras e medidas relacionados ao comportamento do processo.
Habilidade de generalização: após o processo de treinamento, a rede é capaz de
generalizar o
conhecimento adquirido, possibilitando a estimação de soluções que eram até então
desconhecidas.
Exercício 6 Logística: Saída: valores entre 0 e 1. Possui uma flexão mas continua
estritamente crescente. O Beta vai definir se o nível de inclinação vai se aproximar
mais do eixo Y ou não. Quanto maior o Beta, maior a aproximação. Quando ele
tende ao infinito, ela se aproxima da função degrau.
Tangente Hiperbólica: Saída: valores entre -1 e 1. Possui uma flexão mas continua
estritamente crescente. O Beta vai definir se o nível de inclinação vai se aproximar
mais do eixo Y ou não. Quanto maior o Beta, maior a aproximação. Quando ele
tende ao infinito, ela se aproxima da função bipolar.
Exercício 7 = Logistica: Em que a é o parâmetro de inclinação da função sigmóide,
a qual está associada ao nível de inclinação da função em relação ao seu ponto de
inflexão. Sua expressão matemática é dada por:
Tangente Hiperbólica: Ao contrário da função sigmóide, o resultado da saída
sempre assumirá valores reais entre entre -1 e 1. Sua expressão matemática é dada
por:
Exercício 8 = Logística: útil para produzir probabilidades em problemas de
classificação binária, ou seja, trabalha como pertencer ou não pertencer à
determinada classe.
Tangente Hiperbólica: boa para ativação de camadas escondidas, pois ela está
centrada em zero, não possui tanta extremidade quanto a logística. Sua derivada
converge em 0 e mais rapidamente.
Exercício 9 = O parâmetro de velocidade de uma rede neural artificial está
basicamente relacionado com o número de operações por segundo dos
computadores. Considerando um clock da ordem de gigahertz, então um período de
processamento dos neurônios artificiais fica na grandeza de nanossegundo.
Exercício 10 = Foi verificado que sua aplicação demasiada útil e bem sucedida em
diversos setores da sociedade: saúde, economia, transporte, educação, indústria de
máquinas, tudo graças a sua capacidade adaptativa, e ao fato de poder induzi-la a
agir em prol da solução de casos em um nicho ou problema específico.
Capítulo 2
Exercício 1 = Por lote de padrão: os ajustes efetuados nos vetores de pesos das
redes e em seus limiares só são efetivados após a apresentação de todo o conjunto
de treinamento, pois cada passo de ajuste leva em consideração o total de desvios
observados nas amostras de treinamento frente aos respectivos valores desejados
para as suas saídas.
Padrão por padrão: os ajustes nos pesos e limiares das redes são efetuados após a
apresentação de cada amostra de treinamento, portanto, após a execução do passo
de ajuste, a respectiva amostra pode ser descartada.
Exercício 2 = Não necessariamente, feedforward de camadas múltiplas o número
de camadas escondidas e seus respectivos neurônios constituintes dependem,
sobretudo, do tipo e da complexidade do problema a ser mapeado pela rede, assim
como da quantidade e da qualidade dos dados disponíveis sobre o problema.
Exercício 3 = O número de camadas escondidas e seus respectivos neurônios
constituintes dependem, sobretudo, do tipo e da complexidade do problema a ser
mapeado pela rede, assim como da quantidade e da qualidade dos dados
disponíveis sobre o problema.
Exercício 4 = Recorrente: Saídas dos neurônios são realimentadas como sinais de
entrada para outros neurônios. Realimentação as qualificam para processamento
dinâmico de informações.
Feedforward: na camada simples, é constituída de uma camada de entrada e única
camada de neurônios, que é a própria saída. O fluxo de informações segue sempre
numa única direção (unidirecional). Na camada múltipla: Presença de uma ou mais
camadas neurais escondidas. Quantidade de camadas escondidas e de neurônios
dependem, sobretudo, do tipo e complexidade do problema.
Exercício 5 = Podem ser utilizadas em sistemas variantes em relação ao tempo,
como previsão de séries temporais, otimização e identificação de sistemas, controle
de processos, etc.
Exercício 6 =
Exercício 7 = O processo de treinamento consiste da aplicação de passos
ordenados que sejam necessários para sintonização dos pesos sinápticos e limiares
de seus neurônios, tendo-se como objetivo final a generalização de soluções a
serem produzidas pelas suas saídas, cujas respostas são representativas do
sistemas físico em que estão mapeando.
O algoritmo de aprendizagem é o conjunto desses passos ordenados visando o
treinamento da rede. Durante o processo de treinamento de redes neurais artificiais,
cada apresentação completa das amostras pertencentes ao subconjunto de
treinamento, visando, sobretudo, o ajuste dos pesos sinápticos e limiares de seus
neurônios, será denominada de época de treinamento.
Exercício 8 = No modelo de aprendizagem de máquina supervisionada
conseguimos dar os pesos ou calibrar o nível de assertividade e de precisão de um
modelo,dessa forma tende a ter uma necessidade de disponibilizar uma tabela de
dados(E/S) representativa do processo, também conhecida como tabela
atributo/valores. Os pesos sinápticos e limiares são continuamente ajustados diante
a aplicação de ações comparativas.
Diferente do supervisionado, durante a aplicação de um algoritmo de
aprendizado baseado em treinamento, inexistem as respectivas saídas desejadas.
Os pesos sinápticos e limiares dos neurônios da rede são então ajustados pelo
algoritmo de aprendizado de forma a refletir esta representação internamente dentro
da própria rede.
Exercício 9 =Treinamento supervisionado: consiste em se ter disponível disponível,
considerando cada amostra dos sinais de entrada, as respectivas saídas desejadas.
Cada amostra de treinamento é então composta pelos sinais de entradas e suas
correspondentes saídas. Comporta como se houvesseum “professor” ensinando
para a rede qual seria a resposta correta para cada amostra apresentada.
Treinamento com reforço: avaliam constantemente a defasagem de valor entre as
respostas produzidas pela rede em relação à respectiva saída desejada. Os
algoritmos de aprendizagem utilizados ajustam os parâmetros internos dos
neurônios baseando-se em quaisquer informações quantitativas ou qualitativas
advindas da interação com o sistema que esta sendo mapeado, as quais são então
utilizadas para medir o desempenho do aprendizado.
Exercício 10 = Os algoritmos de aprendizado utilizados no treinamento com reforço
ajustam os parâmetros internos dos neurônios baseando-se em quaisquer
informações quantitativas ou qualitativas advindas de interação com o sistema. O
processo de treinamento da rede é realizado por tentativa e erro, pois a única
resposta disponível para uma determinada entrada é se é satisfatória ou não. Se for
considerada satisfatória, incrementa nos pesos sinápticos e limiares são então
gradualmente efetuados visando reforçar esta condição comportamental.
Diversos algoritmos que utilizam treinamento com reforço são baseados em
métodos estocásticos que selecionam probabilísticamente suas ações de ajustes.
Capítulo 03
Exercício 06 = A quantidade de épocas necessárias para a convergência varia em
função dos valores iniciais que foram atribuídos ao vetor de pesos {w}, assim como
da disposição espacial das amostras de treinamento e do valor especificado para a
taxa de aprendizado.
Exercício 7 = O resultado vai variar toda vez que o algoritmo for executado, então
mesmo tendo as mesmas amostras, o resultado será diferente.
Exercício 8 = Se a saída produzida pelo Perceptron está não coincidente com a
saída desejada, os pesos sinápticos e limiares da rede serão então incrementados
proporcionalmente aos valores de seus sinais de entrada; caso contrário, a saída
produzida pela rede é igual ao valor desejado, os pesos sinápticos e limiar
permanecerão então inalterados. Este processo é repetido, sequencialmente para
todas as amostras de treinamento, até que a saída produzida pelo Perceptron seja
similar à saída desejada de cada amostra.
Exercício 9 = Não é possível, pois na figura os dados não são linearmente
separáveis, e a técnica do perceptron não permite isso.
Exercício 10 = Tipicamente, devido às suas características estruturais, as funções
de ativação normalmente usadas no Perceptron são a função degrau ou degrau
bipolar. Assim, independente da função de ativação a ser utilizada, tem-se apenas
duas possibilidades de valores a serem produzidos pela sua saída, ou seja, valor 0
ou 1 se for considerada a função de ativação degrau, ou ainda, valor -1 ou 1 se for
assumida a função degrau bipolar.
Capítulo 4
Exercício 7 =
Exercício 8 = Verdadeira. A rede Adaline não tem relação forte de inicialização dos
pesos à luz dos valores finais do hiperplano ideal. O hiperplano de separabilidade
sempre será o mesmo.
Exercício 9 = Não será pois varia em função da disposição espacial das amostras
de treinamento e do valor assumido para a taxa de aprendizado.
Exercício 10 = Sim, há necessidade de atualização do operador, devido a variação
é a que vai fornecer um indicativo do melhor resultado em que o processo de
treinamento está sendo executado. Assim sendo caso erro, o processo minimiza o
erro quadrático em relação às amostras disponíveis para o aprendizado em forma
decrescente no decorrer das épocas.Mais conteúdos dessa disciplina
 Inteligência_Artificial_e_seus_Impactos_na_Sociedade-1
Inteligência_Artificial_e_seus_Impactos_na_Sociedade-1- GUERRA FRIA - LUCAS
- História IA
- Screenshot_20250429-094755
- Screenshot_20250428-222354
- Screenshot_20250428-221838
- Screenshot_20250428-222233
- Screenshot_20250428-222320
- Screenshot_20250428-221804
- Screenshot_20250428-222205
- Screenshot_20250428-222245
- Screenshot_20250428-222111
- Assinale a afirmativa verdadeira a respeito do planejamento de agentes inteligentes em inteligência artificial:
A. controlador é responsável por el...
- A respeito dos métodos de planejamento vistos: planejamento progressivo, regressivo e o strips.
Assinale a alternativa verdadeira:
A - Planejamento...
- Em relação aos assistentes pessoais virtuais, pode-se afirmar que:
I - A criação de assistentes pessoais virtuais é uma das aplicações de IA mais u...
- Prolog utiliza cláusulas para definir relações e regras.
O que significa a cláusula mortal (X) :- humano (X) em Prolog?
A Todos os mortais são huma...
- O paradigma conexionista, também conhecido por redes neurais artificiais, forma um paradigma de IA que tem inspiração no comportamento do cérebro, ...
- Considere um sistema nebuloso com as seguintes especificações: 28/04/2025, 21:26 Variáveis de Entrada: E1 E2 e12 e13 e21 e22 e23 0 30 40 60 70 100 ...
- As redes neurais são úteis para modelar e resolver diversas categorias de problemas.
Nesse sentido, selecione a opção correta a respeito das aplica...
- A tecnologia por trás das baterias modernas está em constante evolução. Há muito tempo se fala dos acumuladores estado sólido, mas o aumento dos cu...
- Uma equipe de cientistas afirma ter desenvolvido uma técnica de "autocura" que pode limpar possíveis dendritos enquanto a bateria de potássio carre...
- Todos os dias, milhares de pilhas e baterias são descartadas, muitas delas de forma inadequada. Esse grande volume de resíduos perigosos representa...
- Seguir padrões específicos, basicamente, minimizam as chances de erros e falhas. É possível destacar as vantagens: Reduzir a ocorrência de falhas n...
- A Europa há décadas vem sendo um dos grandes polos mundiais de produção de motores de combustão interna, mas à medida que o setor faz sua transição...
- Segundo a norma ABNT NBR 15941:2019, no teste de capacidade real em regime de 10 h: A bateria é considerada aprovada se o valor da capacidade obtid...
- História da Eva na Educação Física
- Língua Inglesa: Objetos Escolares





Mais conteúdos dessa disciplina
- Inteligência_Artificial_e_seus_Impactos_na_Sociedade-1
- GUERRA FRIA - LUCAS
- História IA
- Screenshot_20250429-094755
- Screenshot_20250428-222354
- Screenshot_20250428-221838
- Screenshot_20250428-222233
- Screenshot_20250428-222320
- Screenshot_20250428-221804
- Screenshot_20250428-222205
- Screenshot_20250428-222245
- Screenshot_20250428-222111
- Assinale a afirmativa verdadeira a respeito do planejamento de agentes inteligentes em inteligência artificial:
A. controlador é responsável por el...
- A respeito dos métodos de planejamento vistos: planejamento progressivo, regressivo e o strips.
Assinale a alternativa verdadeira:
A - Planejamento...
- Em relação aos assistentes pessoais virtuais, pode-se afirmar que:
I - A criação de assistentes pessoais virtuais é uma das aplicações de IA mais u...
- Prolog utiliza cláusulas para definir relações e regras.
O que significa a cláusula mortal (X) :- humano (X) em Prolog?
A Todos os mortais são huma...
- O paradigma conexionista, também conhecido por redes neurais artificiais, forma um paradigma de IA que tem inspiração no comportamento do cérebro, ...
- Considere um sistema nebuloso com as seguintes especificações: 28/04/2025, 21:26 Variáveis de Entrada: E1 E2 e12 e13 e21 e22 e23 0 30 40 60 70 100 ...
- As redes neurais são úteis para modelar e resolver diversas categorias de problemas.
Nesse sentido, selecione a opção correta a respeito das aplica...
- A tecnologia por trás das baterias modernas está em constante evolução. Há muito tempo se fala dos acumuladores estado sólido, mas o aumento dos cu...
- Uma equipe de cientistas afirma ter desenvolvido uma técnica de "autocura" que pode limpar possíveis dendritos enquanto a bateria de potássio carre...
- Todos os dias, milhares de pilhas e baterias são descartadas, muitas delas de forma inadequada. Esse grande volume de resíduos perigosos representa...
- Seguir padrões específicos, basicamente, minimizam as chances de erros e falhas. É possível destacar as vantagens: Reduzir a ocorrência de falhas n...
- A Europa há décadas vem sendo um dos grandes polos mundiais de produção de motores de combustão interna, mas à medida que o setor faz sua transição...
- Segundo a norma ABNT NBR 15941:2019, no teste de capacidade real em regime de 10 h: A bateria é considerada aprovada se o valor da capacidade obtid...
- História da Eva na Educação Física
- Língua Inglesa: Objetos Escolares